Resolve performance issues and detect problems before they affect end customers or impair system performance.
Becoming more efficient in addressing the time spent on troubleshooting and root cause analysis is more difficult with the emergence of more dynamic complex environments with more volume, variety, and data velocity.
IT Operational challenges:
- IT/network complexity is outpacing human capabilities
- Traditional siloed operations limits organizational intelligence
- Operational issues heighten managing and integrating large, complex data sets
- Legacy can’t keep up with the rapid growth in data volumes and the pace of change
- Operational costs are accelerating

Real Business Value Delivered to Vitria AIOps Customers
Reduction in incidents by 65%
Improved efficacy 20% annually
Service availability improved by 60 %
Reduced technician dispatches by 250,000
saving $16 million in Opex
Customer support contacts reduced by 18%
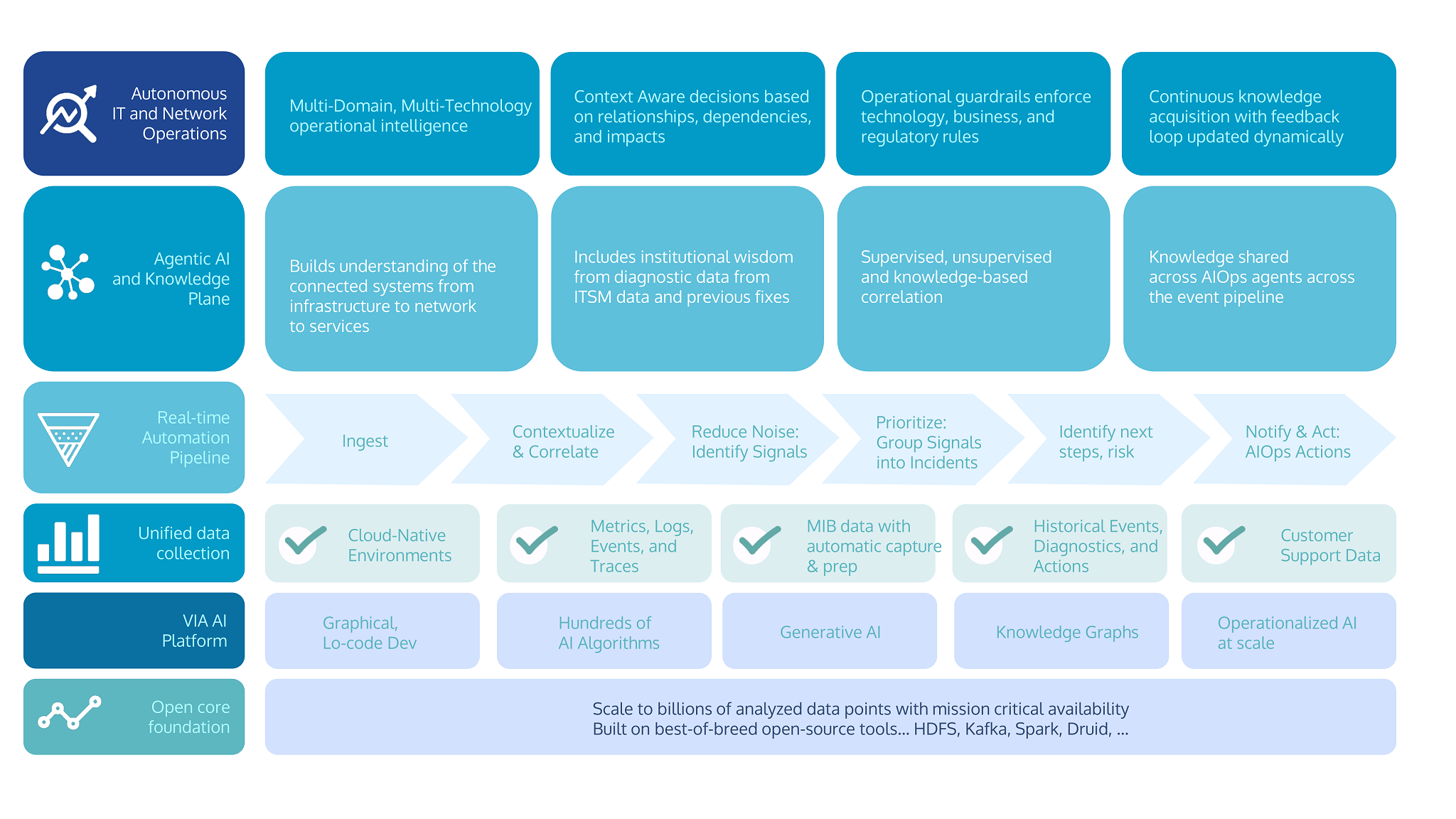
VIA AIOps Features
Learn more about VIA AIOps key features by clicking the feature icons.

- Scales to billions of analyzed data points
- Supports mission critical applications reliably
- Enables integration with existing service management and monitoring systems
- Built on best of breed open-source tools – HDFS, Kafka, Spark, Druid…

- Enables explainable, trusted automation AI+Knowledge® embedded inside workflows
- Uses knowledge graphs, telemetry, and multi-agent AI to create a system of understanding
- Operationalized AI at scale

- Accepts metrics, logs, event and trace data
- Ingests data via native connectors from applications, network and monitoring tools
- Onboards raw data in standard and non-standard formats
- Collects and runs data in cloud-native environments from a wide range of sources
- Ingests never before seen data in less than one hour with VIA’s Streaming Onboarding
- Does not require data to fit a specific data model or data specifications
- Eliminates the development of thousands of lines of code to ingest and parse data sets
- Automates the preparation and capture of MIB data for use in fault and performance management
- Supports historical event, diagnostics, and action data, as well as customer support data

- Ingest and aggregate metrics/events
- Contextualize and correlate
- Reduce noise and detect signals
- Group signals into incidents and prioritize
- Evaluation of severity, impact and causation
- Notify and take AI action

- Automatically learns the service topology, system dependencies, and the relationships between the network and services running on it
- Incorporates the institutional wisdom extracted from ITSM data and remediation workflows for next steps and automation
- Includes operational guardrails provided through semantic dictionaries enforcing technology, business, and regulatory rules on AI behavior

- Enablement of the journey to automated resolution and self-healing
- Incident Management process automation across infrastructure, application, and services
- Multi-step autonomous execution from diagnose, decide, remediate, and validate
- Explainability traced back to relationship, learned patterns, and known resolution
VIA AIOps End-to-End Service Assurance
Resources





